
Controllable Agent for Complex RAG Tasks
Standard RAG systems follow a fixed retrieve-and-generate pipeline that works well for simple factual questions but struggles with complex queries that require multiple retrieval steps, different strategies for different parts of the question, or domain-specific retrieval logic. Controllable agents solve this by putting a reasoning layer between the user's question and the retrieval system, allowing the agent to dynamically choose and sequence retrieval strategies based on query complexity.
A controllable RAG agent operates differently from a standard RAG pipeline. Instead of always performing the same vector similarity search, it first analyzes the query to understand what kind of information is needed, then selects the appropriate retrieval strategy (semantic search, keyword search, metadata filtering, multi-hop retrieval, or a combination), executes the retrieval, evaluates whether the results are sufficient, and optionally performs additional retrieval rounds to fill information gaps. The "controllable" aspect means the user can guide this process, specifying preferred retrieval strategies, setting quality thresholds, or requiring the agent to explain its retrieval decisions.
This transparency is crucial for production RAG systems where users need to trust the results. When a controllable agent explains "I found 3 relevant documents using semantic search and 2 using date-filtered keyword search, but I'm not confident about the pricing data, would you like me to search the contracts database specifically?", that's dramatically more useful than a black-box system that silently retrieves whatever its default strategy finds. The article covers concrete implementation patterns: query analysis prompts, retrieval strategy routing, result evaluation metrics, and user-interaction protocols for guided retrieval. These patterns work with any vector database and any LLM provider.
TL;DR
How to build controllable agents that handle complex RAG workflows, with user-guided retrieval strategies and transparent decision-making.
Key Takeaways
Controllable RAG agents dynamically choose retrieval strategies based on query complexity, not locked into a single fixed pipeline.
The agent analyzes queries, selects strategies (semantic, keyword, metadata, multi-hop), evaluates results, and fills gaps with additional retrieval.
User-guided retrieval and transparent decision-making build trust, the agent explains its retrieval choices and asks for guidance when uncertain.
These patterns work with any vector database and LLM, they're architecture-level improvements, not framework-specific features.
**The full code tutorial is available here**
Introduction
Nowadays, with the rise of large language models, everyone wants to talk with their data and ask questions about it. As a result, Retrieval-Augmented Generation (RAG) has become very popular. The standard RAG pipeline consists of data ingestion and retrieval (with many techniques to optimize these steps for your specific problem and data), followed by feeding a user query with the retrieved information to the LLM to generate the response.
However, in some cases, both the data and the questions we want to ask are not trivial. These situations require a more sophisticated agent with reasoning capabilities to go through several steps to solve the question. In this article, I will show you how I tackled this problem, using the first book of Harry Potter as a use case.
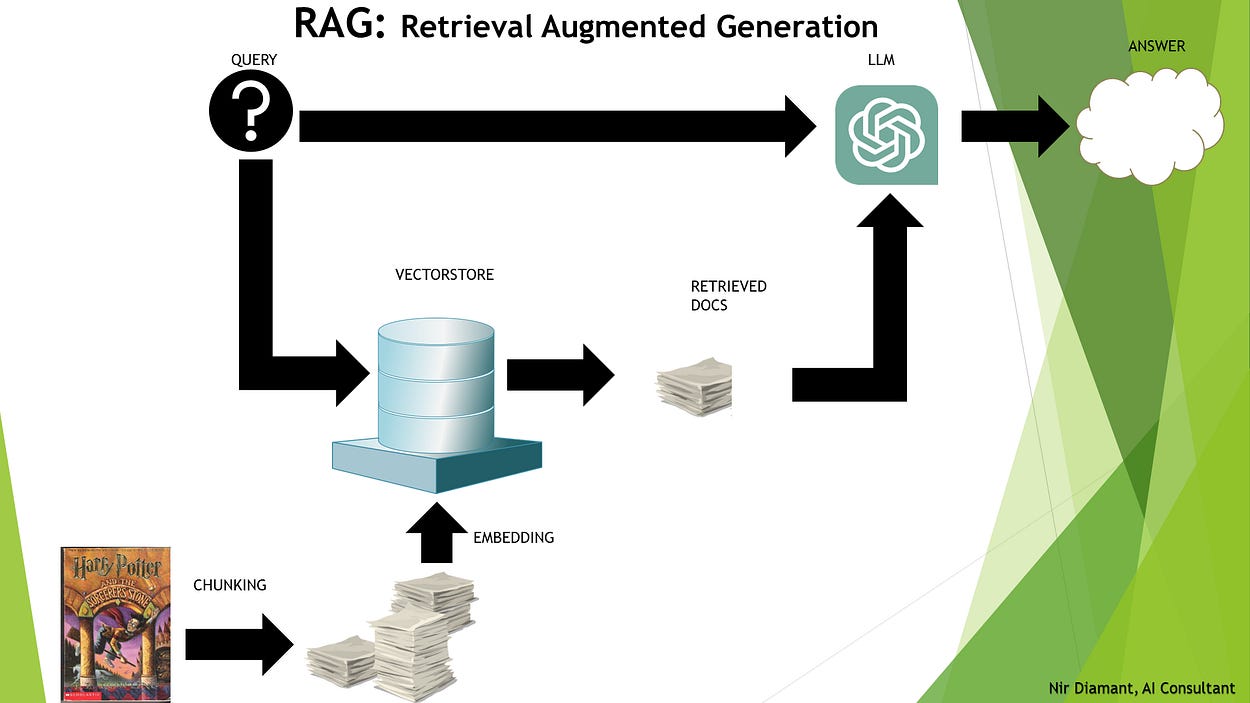
Understanding RAG and Agents
We’ve talked a bit about what RAG is, but what are Agents in the field of LLMs?
LLM agents are advanced AI systems designed for creating complex text that needs sequential reasoning. They can think ahead, remember past conversations, and use different tools to adjust their responses based on the situation and style needed.

Limitations of Semantic Similarity in Retrieval
Traditional RAG systems often rely on semantic similarity for retrieval. This approach measures how close the meanings of two pieces of text are to each other, typically using vector representations and similarity scores. While effective for simple queries, it falls short for complex tasks that require multi-step reasoning or understanding of broader context. The semantic similarity might retrieve relevant individual chunks but struggles with questions needing information synthesis or logical inference across multiple sources.
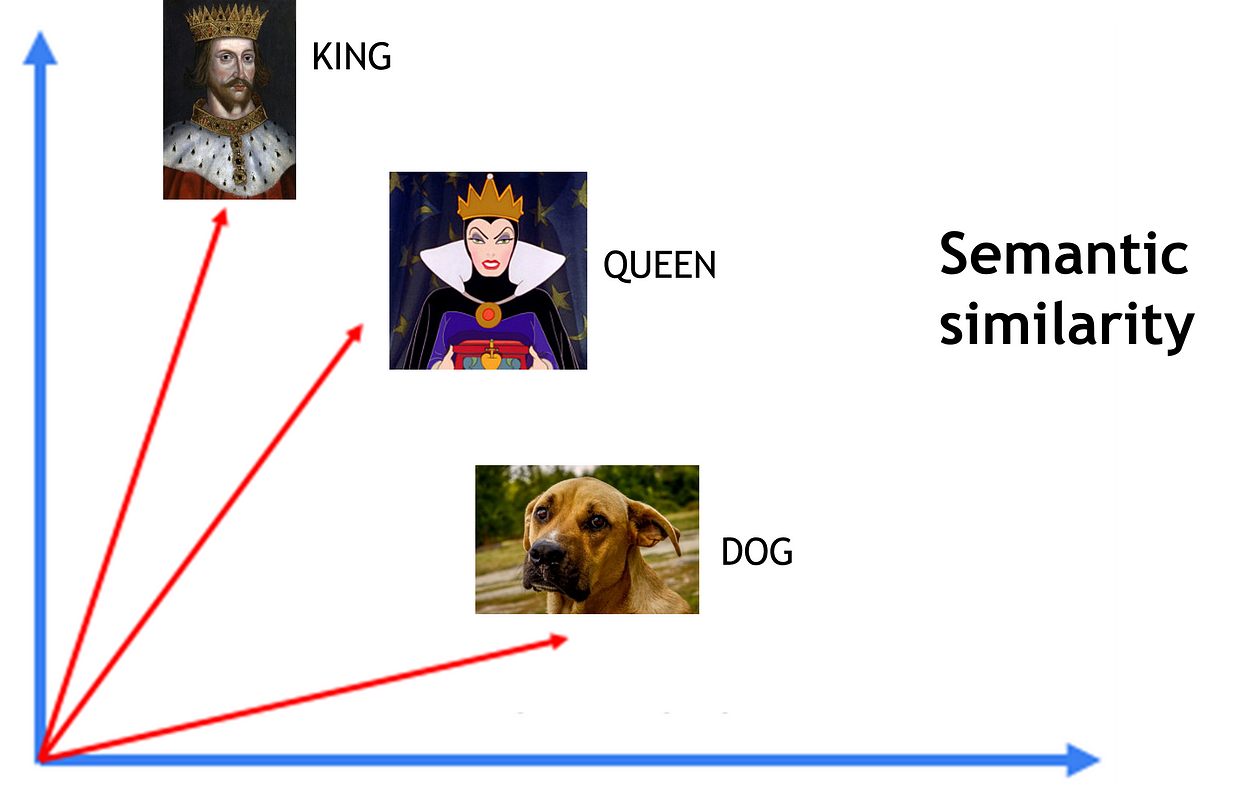
The Challenge with Regular Agents
The challenge with regular agents lies in balancing the level of autonomy we grant them with the control we retain. An alternative approach is to construct our own workflow.
Issues with regular agents:
Lack of control over when and in what order tools are used.
No control over the conclusions drawn from tool usage.
Difficulty in tracing hallucinations or reliance on pre-trained knowledge.
Advantages of workflow engineering:
Enables the definition of a specific, structured path to address the problem.
Provides full control over each step in the process.
However, it requires a tailored solution, which can be time-consuming and complex to design as the problem becomes more challenging.
Our Mission: Creating a Controllable Agent for Complex RAG Tasks
Now that we understand RAG and Agents, let’s embark on our mission to create an agent capable of solving complex RAG tasks while maintaining control over its operations.
For this, we’ll utilize three types of vector stores:
Regular Vector Store: Contains book chunks for general context.
Chapter Summary Vector Store: Provides higher-level, granular information.
Quote Vector Store: Stores specific quotes from the book for detailed, high-resolution information.
A Naive Flow for Engineering an Agent to Validate a RAG Pipeline:
Context Retrieval: The process begins by retrieving context relevant to the given question.
Filtering: The retrieved context is filtered to retain only the most relevant content.
Question Answering: The agent attempts to answer the question using the refined context.
Evaluation: The answer is evaluated for relevance and potential hallucinations:
If the answer is relevant and not a hallucination, the process ends successfully.
If the answer is a hallucination but contains useful elements, the agent retrieves additional context.
If the answer is irrelevant or unhelpful, the question is rewritten.
Iteration: The rewritten question is sent back to the context retrieval step, and the process repeats until a satisfactory answer is produced.
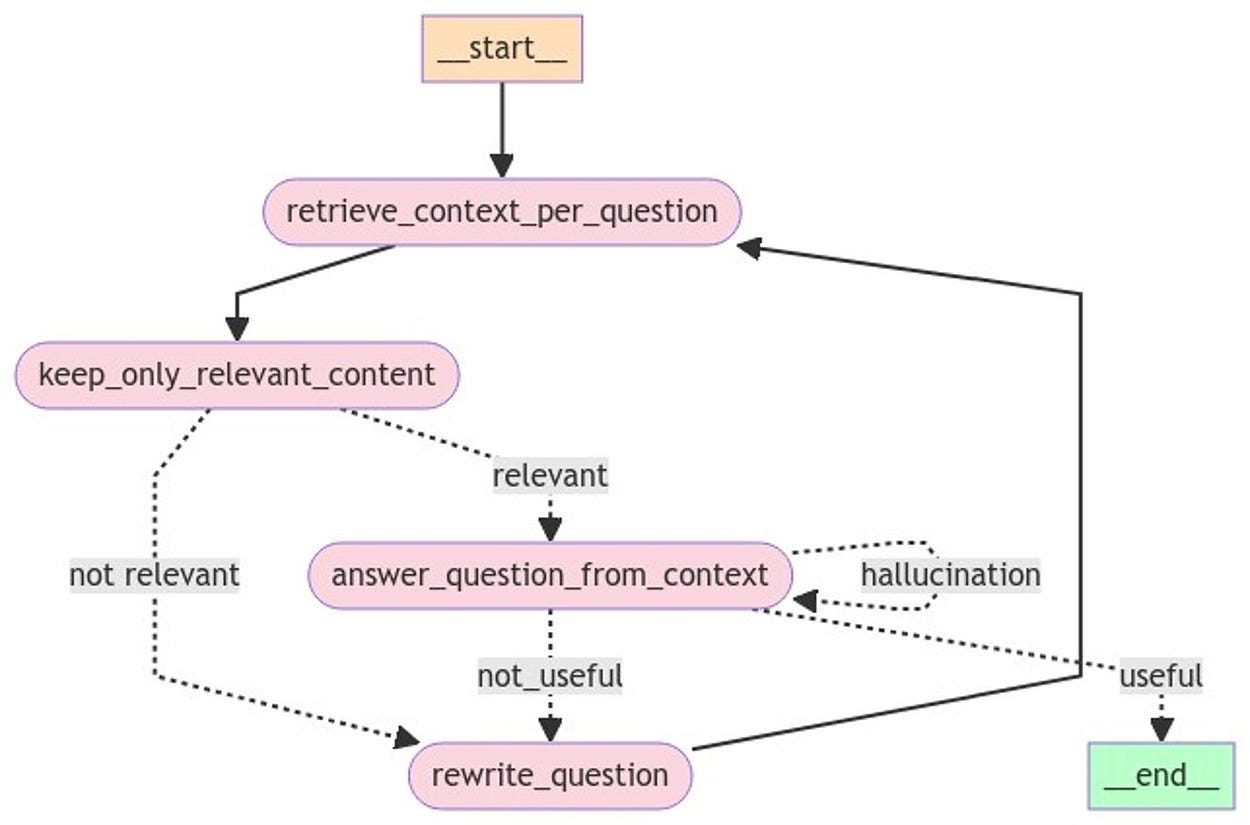
This could have been a nice solution, but it is not enough for complex questions.
Example: Complex Question Solving
Let’s consider an example of a complex question requiring reasoning:
“How did the protagonist defeat the villain’s assistant?”
To solve this question, the following steps are necessary:
Identify the Protagonist: Determine who the protagonist of the plot is.
Identify the Villain: Establish who the main antagonist is.
Identify the Villain’s Assistant: Determine who serves as the assistant to the villain.
Search for Relevant Interactions: Locate instances of confrontations or interactions between the protagonist and the villain’s assistant.
Deduce the Reason: Analyze the context to understand how and why the protagonist defeated the assistant.
Required Capabilities
Hence, the capabilities required for our solution are:
Tools: To facilitate retrieval and answering tasks effectively.
Reasoning: To deduce logical steps and derive meaningful conclusions.
Flow: To ensure a structured and coherent process throughout.
Control: To maintain oversight and adjust the solution dynamically as needed.
Verification: To validate the accuracy and grounding of the generated answers.
Stop Condition: To define when the process should terminate, ensuring efficiency.
Evaluation: To assess the solution’s relevance, reliability, and overall quality.

Implementation Components
The tools we may use in our case should include retrieval and answering. This involves breaking the previous graph into several subgraphs that will serve as tools for the new agent graph.
For reasoning and flow, we may need the following components:
Planner: Constructs a plan of steps needed to answer a given question and arrive at the final solution.
Step Breakdown Component: Breaks down the plan into steps for either retrieval or answering tasks.
Task Handler: Determines which tool to use at each step of the process.
Re-plan Component: Updates the plan dynamically based on progress, previous steps completed, and the information gathered at each stage.
Retrieval and Answer Tools: Designed as small agents themselves. These tools are monitored to ensure they clean retrieval information, verify grounding on the context, and perform hallucination checks.
(Optional) Question Anonymization Component: Generates a general plan without biases that could arise from prior knowledge of any LLM.
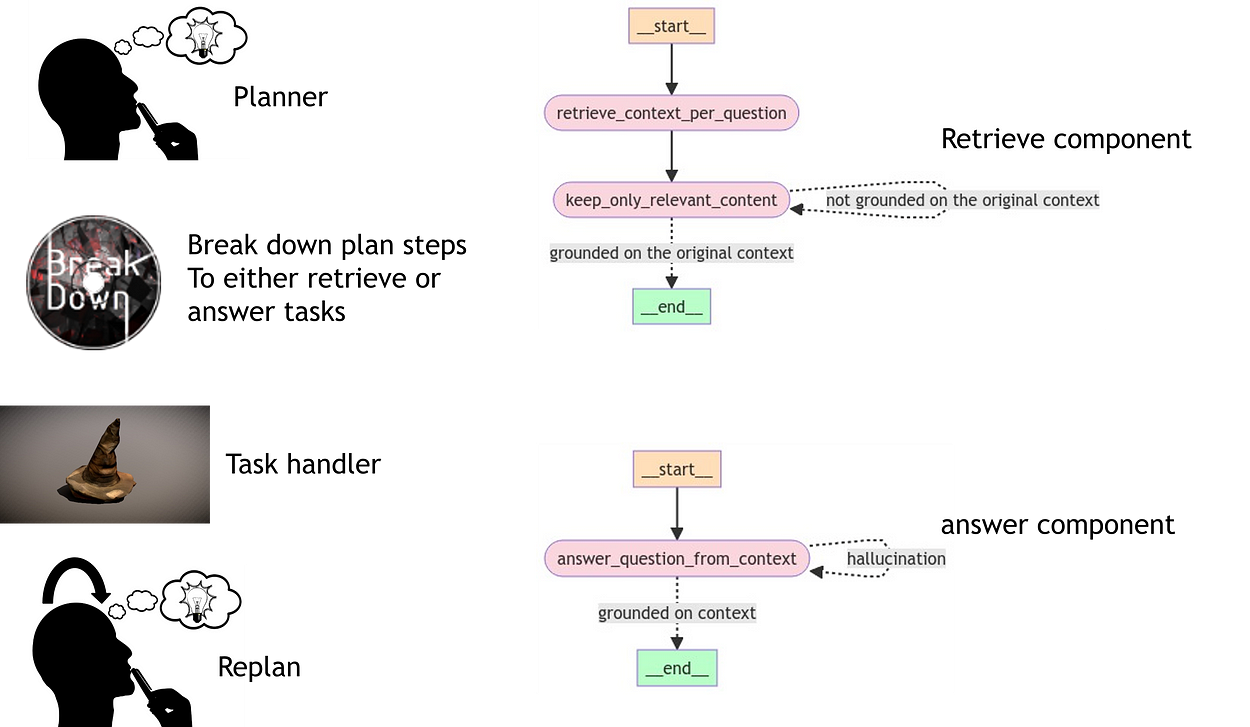
Stop Condition
How to Determine When the Process is Complete?
There are several possible strategies:
Answer Check at Re-plan Visits:
At each re-plan step, evaluate whether the question can already be answered using the aggregated information collected so far.Saturation Threshold:
Continue collecting relevant data until the process reaches a point of saturation, where the amount of new, useful information falls below a predefined threshold.Predefined Iteration Limit:
Limit the depth or recursion of the graph by setting a maximum number of iterations to avoid over-processing or unnecessary complexity.
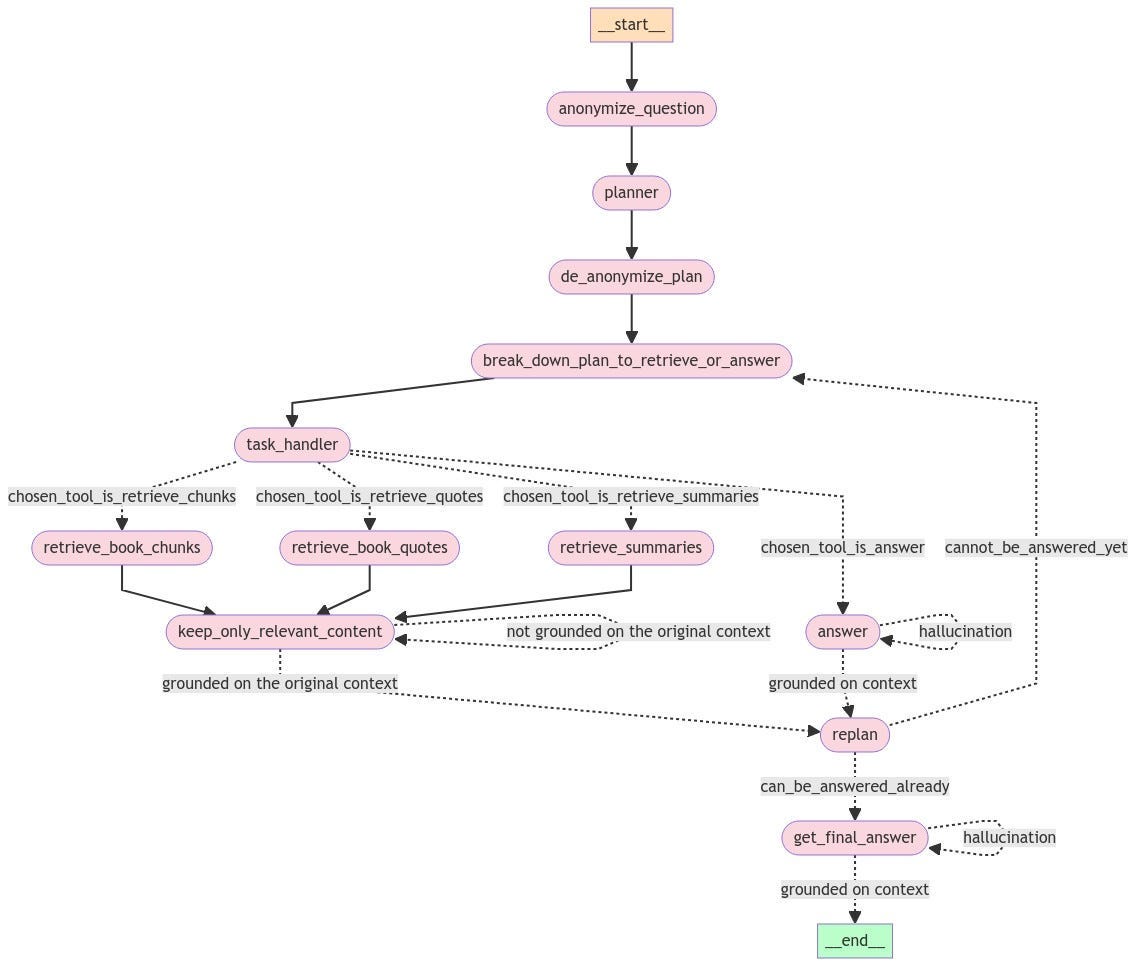
The full agent logic
The Controllable Agent for Complex RAG Tasks
The agent follows a sophisticated, multi-step process to tackle complex queries with precision and control:
Question Anonymization:
The process starts by anonymizing the input question to minimize biases.Plan Creation:
A planner constructs a general plan to answer the anonymized question.De-anonymization:
The plan is de-anonymized to reintroduce specific context from the original question.Task Breakdown:
The plan is divided into a series of retrieve or answer tasks.Task Handling:
A task handler selects the appropriate tool for each task, such as:Retrieving book chunks
Retrieving book quotes
Retrieving summaries
Answering the question directly
Information Retrieval:
For retrieval tasks, the system fetches relevant information and filters it to retain only the most pertinent content, ensuring it’s grounded in the original context.Answer Attempt:
If the task is to answer the question, the system formulates a response based on the retrieved context.Answer Verification:
The answer is evaluated for hallucinations and checked to ensure it is grounded in the provided context.Replanning Phase:
If the question remains unanswered or the answer is unsatisfactory, the system enters a replanning phase to revise the approach.Replan Evaluation:
During replanning, the system assesses whether the question can be answered with the current information or if further retrieval is necessary.Final Answer Retrieval:
If the question can be answered, the system generates the final response.Final Verification:
The final answer undergoes another round of checks for hallucinations and contextual grounding.Process Completion:
If the final answer passes all verification steps, the process concludes successfully.
Conclusion
This iterative, multi-faceted approach enables the agent to handle complex queries effectively by breaking them into manageable tasks, retrieving relevant information, and continuously refining its methods until a well-grounded and satisfactory answer is achieved.
Evaluation
Since this is a RAG task, we can evaluate it using methods similar to those for other RAG tasks. For this evaluation, I chose a custom benchmark based on a QA bank, using the following metrics:
Answer Correctness: Evaluates whether the generated answer is factually accurate.
Faithfulness: Assesses how well the retrieved information supports the generated answer.
Answer Relevance: Measures how closely the generated answer addresses the question.
Answer Similarity: Quantifies the semantic similarity between the generated answer and the ground truth answer.
Conclusion
By implementing this controllable agent for complex RAG tasks, we achieve a balance between autonomy and control. This approach enables the generation of more accurate and traceable responses to sophisticated queries. It also opens new possibilities for interacting with and extracting insights from large bodies of text, such as novels or technical documentation.
A lecture I gave on this work:
If you found this article informative and valuable, and you want more:
Related Tutorials
Free Resources
Download free guides, cheatsheets, and templates curated from 130+ tutorials on RAG, AI Agents, and Prompt Engineering.
Also available on Substack
Prefer Substack? This article is also on our newsletter, read by 40K+ AI engineers.
Related Articles
Your First AI Agent: Simpler Than You Think
A beginner-friendly guide to building your first AI agent from scratch, covering what agents really are, how they work, and step-by-step instructions to build one.
How to Choose Your AI Agent Framework
A practical comparison of AI agent frameworks, when each shines, their trade-offs, and how to choose the right tool for your project.
How to Stop AI Hallucinations
AI hallucinations are one of the biggest challenges in production AI. Here are battle-tested techniques to minimize and control them.
Get More AI Insights Weekly
Join 40K+ AI engineers getting deep dives on agents, RAG, and prompt engineering every week.